研究大牛的作品是接近大牛的必要步骤——膜Linus Torvalds
版本控制的发展历史
创建一个README.md文件,写入两行文字:Git is a distributed, open source version control system.
You can install git on Linux using binary release.
我们将它作为这个文件的第一个版本,之后有一天,我想再对它做一点修改:Git is a distributed, open source version control system.
You can install git on Linux, Windows using binary release.
Or you can compile from source code.
在版本控制系统还没有出现之前,人们总是用不同的文件名来区分不同的文件版本。如果想未来能回滚到之前的版本,此时只能用README_2.md来去分它。随着版本越来越多,文件名越来越长,管理大量版本的文件成为了噩梦。
1991-2002之间,即使CVS工具已经出现,但Linus一直使用diff和patch管理源码。diff和patch是对源码版本控制的两个最基本的概念。如今依然可以在Linux上直接使用这两个命令。diff是一个对比目录和文本文件差异的工具,在Linux上使用diff -u README.md README_2.md可以看到如下输出:--- README.md 2022-07-10 15:56:19.638578324 +0800
+++ README_2.md 2022-07-10 15:58:49.333566672 +0800
@@ -1,2 +1,3 @@
Git is a distributed, open source version control system.
-You can install git on Linux using binary release.
+You can install git on Linux, Windows using binary release.
+Or you can compile from source code.
输出中详细说明了两个文件修改时间的差异,内容的差异。README.md相比README_2.md修改了一行,新增了一行,此时不难发现diff输出中包含了两个版本之间切换的充分信息。patch是一个文件版本修改工具,patch可以将一个旧版本的文件依据一个diff文件修改成新一个版本的,也可以将一个新版本的文件恢复到旧版本。将刚才的diff输出保存成文件diff.txt:diff -u README.md READMD_2.md > diff.txt,然后使用patch README.md diff.txt就可以将READMD.md修改成新版本,而用patch -R READMD_2.md diff.txt就可以将新版本的README_2.md切换成老版本。
flowchart LR
v1(README.md) ---->| patch README.md diff.txt| v2(README_2.md)
v2 ---->| patch -R README_2.md diff.txt| v1
subgraph R [version 2]
v2
end
subgraph L [version 1]
v1
end
最早的版本控制工具RCS(Revision Control System)就是基于diff和patch实现了版本管理。通过在本地管理各个版本的diff文件,对外提供一套版本控制接口从而实现版本控制。
flowchart LR
subgraph computer [diff files]
v1(version 1)
v1 --> v2(version 2)
v2 --> v3(version 3)
end
file(File) --> v1
CVS(Concurrent Versions System)于1985年诞生,是第一个被大规模应用的集中式版本控制工具,CVS使得多人协作开发成为可能。但CVS不支持原子化的提交,多人同时提交时可能会出现数据不完整的问题,于是SVN(Subversion)诞生了,它可以看作是改进版的SVN,实现了原子化的提交并优化了性能。但SVN还是集中式的版本控制工具,由于集中式的版本控制工具提交代码需要用到网络传输,导致延迟很大,提交需要排队;其次,集中式的存储导致服务器容易因为单点故障和黑客攻击丢失数据。
flowchart LR Host1 --network--> Server Host2 --network--> Server Host3 --network--> Server subgraph Host1 [Host1] F1(File) end subgraph Host2 [Host2] F2(File) end subgraph Host3 [Host3] F3(File) end subgraph Server [Remote Server] ServerRepo end subgraph ServerRepo [Version Control Repo] v1(version 1) --> v2(version 2) v2 --> v3(version 3) v3 --> v4(version 4) end
Linus坚定的反对使用集中式的版本控制工具,选择使用商业版的分布式版本控制工具BitKeeper,并于2005年开发分布式的版本控制工具Git,之后就一直使用Git来管理Linux源码。Git在每台设备上都有一个本地仓库,所以提交代码不涉及网络传输,只有将代码同步到服务器上才需要网络传输。由于分布式的设计,每台设备都可以作为服务器,有效的避免了单点故障和黑客攻击带来的数据损失。
flowchart LR subgraph Local2 [Host2] LocalRepo2 end subgraph LocalRepo2 [Local Git Repo] l2v1(version 1) --> l2v2(version 2) l2v2 --> l2v3(version 3) end subgraph Server [Remote Git Server] ServerRepo end subgraph ServerRepo [Git Repo] v1(version 1) --> v2(version 2) v2 --> v3(version 3) end subgraph Local1 [Host1] LocalRepo1 end subgraph LocalRepo1 [Local Git Repo] l1v1(version 1) --> l1v2(version 2) l1v2 --> l1v3(version 3) end Local1 <--> Server Local1 <----> Local2 Local2 <----> Server
Git快照机制
Git最大的特点就是快,除了得益于分布式的设计(本地代码仓),还得益于它独特的快照机制。分布式版本控制工具和集中式版本控制工具最主要的区别就是其对待数据的方式。
CVS、SVN等工具将文件的版本看作文件相对于原始版本的累计差异,存储版本也是存储原始版本文件已经各个版本的文件变更列表。
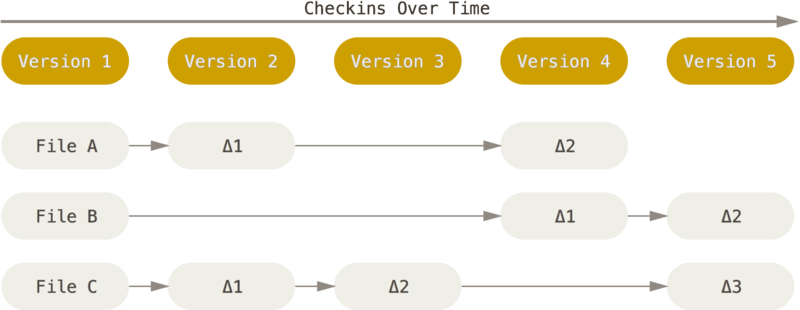
这种实现方式存在的问题就是,后续版本的信息依赖之前所有版本的信息,如果丢失一个版本的信息,后续的版本数据都会失效。获取某个版本的数据需要从第一个版本叠加计算之后的变更信息,所以性能较差。
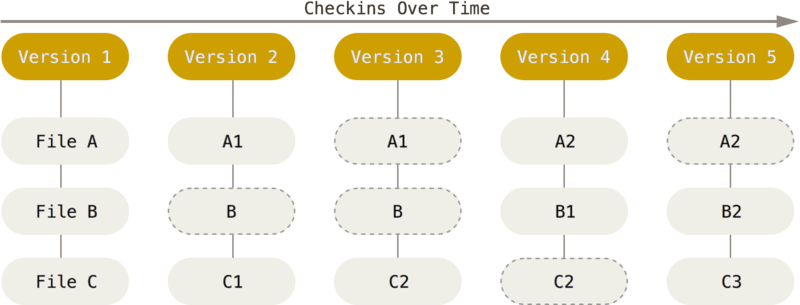
Git则是记录和组装一系列快照流的微型系统,只关心文件数据的整体是否发生变化,而不是具体的文件内容。每次commit的时候保存一次快照,而每个快照都包含了完整的数据。相比与计算文件变更的叠加结果,创建快照和读取快照都是可以一瞬间完成,这就是为什么Git的性能如此之强的原因。
关于文件快照的原理我将在另一篇博客中再做详细说明:深入理解文件快照